• Home
• Research
• Projects
• Patents
• Press
• Demos
• Code
• Teaching
• Talks
• People
• Contact
• CV
• Music
Projects
Disparity estimation in natural stereo-images
The left and right eyes have different vantage points on the world. Binocular disparities are the differences in the left and right images eyes due to these different vantage points. In part because of the recent stereo-3D movie craze, disparity is the depth cue best known to the general public. It is by far the most precise depth cue available to humans. Large psychophysical and neurophysiological literatures exist on disparity processing.
Disparity is used to fixate the eyes and to estimate depth. However, before binocular disparity can be used in service of these tasks, the disparities themselves must first be estimated. To do that, it must be determined which part of each eye's image corresponds to the other. This problem is known as the correspondence problem. Once correspondence is established, it is straightforward to determine the disparity- i.e. subtract the position of a corresponding point in the right eye from its analog in the left. Establishing correspondence, however, is a difficult problem and one that has not been attacked systematically in natural images.
There have been many attempts at solutions. Initial attempts were 'feature-based'. They picked out features readily identified in both images (e.g. a strawberry) and went from there. These theories, however, were hard to make rigorous in absence of a homunculus. These days, local cross-correlation (which provides a measure of local image similarity) is considered the most successful computational model of the correspondence problem. It has been successfully used to predict multiple aspects of human performance. In neuroscience, the disparity energy model is widely accepted as an account of disparity sensitive mechanisms in visual cortex. However, the rules that optimally link the responses of binocular neurons to estimates of disparity remain unknown.
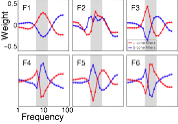
We developed a framework for (i) determining the optimal receptive fields for encoding image information relevant for processing disparity and (ii) processing the encoded information optimally to obtain maximally accurate, precise estimates of disparity in natural images. The optimal filters bear strong similarities to receptive fields in early visual cortex; the optimal processing rules can be implemented with well-established cortical mechanisms. Additionally, this ideal observer model predicts the dominant properties of human performance in disparity discrimination tasks.
This work provides a concrete example of how neurons exhibiting selective, invariant tuning to stimulus properties not trivially available in the retinal images (e.g. disparity) can emerge in neural systems. Cortical areas having such neurons have also been fundamentally important for systems neuroscience. Neurons The capacity for constancies is ability to represent certain behaviorally relevant variables as constant given great variation in the retinal images. Such constancies are one of the great successes of sensory-perceptual systems.


Speed estimation in natural image movies
The images of objects in the world drift across the retina at different speeds dependent on how far away the objects are from the viewer. For example, when looking at the mountains out the window of a car traveling down the highway, the image of the guard rail is drifting across your retina very quickly, the image of cows in the pasture is drifting more slowly, and the image of the mountains in the distance are hardly drifting at all. Motion parallax is the term used to refer to these differential speeds. It is an important and ubiquitous cue to depth.
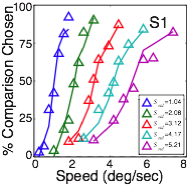
Before depth can be computed from motion parallax, the speed of motion at each retinal location must be determined. To obtain maximally accurate estimates of the speed at each retinal location, we developed an ideal observer model that incorporates the statistics of natural stimuli and the constraints imposed by the front-end of the visual system. Estimation performance is unbiased, and decreases in precision as speed increases.
We pitted ideal and human observers against each other in matched speed discrimination tasks. Both types of observers were shown the same large, random set of natural image movies. Human performance closely tracks ideal performance, although ideal performance was somewhat more precise. However, a single free parameter, which accounts for human computational inefficiencies (e.g. internal noise), provides a close quantitative account of the human data. This result shows that a task-specific analysis of natural signals can quantitatively predict (to a scale factor) the detailed features of human speed discrimination with natural stimuli.
The classic approach to modeling perceptual performance is a two step process. First, one collects a set of behavioral data by presenting the same (or a small number of) stimuli many hundreds of times, Second, one develops a model that fits the data. This approach has been useful because it provides compact descriptions of large, complicated datasets. However, this approach does not provide a gold standard against which human performance can be benchmarked.
By measuring the task-relevant properties of natural stimuli and the constraints imposed by the visual system's front-end, one can determine the theoretical limit on performance. Human observers track but fall short of this theoretical limit. A single free parameter, that captures human inefficiency, across for the great majority of human behavioral variability. This result is impressive, but it leaves unanswered the question of why humans fall short of theoretically achievable performance limits. Humans could fall short because they are performing suboptimal computations, because of internal noise, or because of some combination of the two.



Estimating surface orientation from local cues in natural images
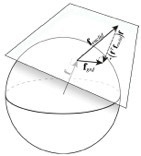
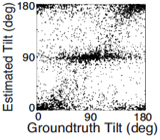
Estimating the 3D shape of objects is a critical task for sighted organisms. Accurate estimation of local surface orientation is an important first step in doing so. Surface orientation must be described by two parameters; in vision research, we parameterize it with slant and tilt. Slant is the amount by which a surface is rotated out of the reference (e.g. frontoparallel) plane. Tilt is the direction in which the surface is receding most rapidly. For example, the ground plane straightahead is a frequently encountered surface having a tilt of 90 deg. (Tilt is the projection of the surface normal into the reference plane, see below).


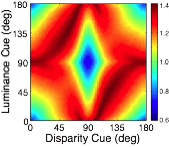
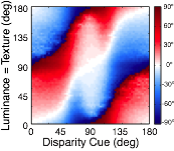
Many image cues provide information about surface orientation, but most are quite poor in natural scenes. The visual system nevertheless manages to combine these cues to obtain accurate estimates of shape. Thus, it is critical to understand how multiple cues should be combined for optimal shape estimation. In this work, we examine how gradients of various image cues— disparity, luminance, texture—should be combined to estimate surface orientation in natural scenes. We start with tilt.
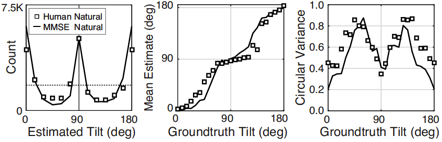
A rich set of results emerges. First, the prior probably distribution over surface tilts in natural scenes exhibits a strong cardinal bias. Second, the likelihood distributions for disparity, luminance, and texture are each somewhat biased estimators of surface tilt. Third, the optimal estimates of surface tilt are more biased than the likelihoods, indicating a strong influence of the prior. Fourth, when all three image cues agree, the optimal estimates become nearly unbiased. Fifth, when the luminance and texture cues agree they often veto disparity in the estimate of surface tilt, but when they disagree, they have little effect.
We have now used these results to design and run experiments to test whether humans estimate tilt in accordance with the minimum-mean-squared-error estimator. Humans perform very much like the model across an array of stimulus-by-stimulus, summary measures (e.g. estimate counts, means, variances), and spatial pooling behavior. Natural scene statistics guide the manner in which humans estimate surface tilt.

Stereo-images of natural scenes with co-registered range data
Much of our work on estimating and interpreting depth cues relies on knowing what the right answer (or groundtruth) is. For example, to evaluate the accuracy of a depth-from-disparity algorithm, it is necessary to know with certainty what the true disparities are. To obtain such a database, we constructed a Frankensteinian device. The device consisted of a digital SLR camera mounted atop a laser range scanner all mounted atop a custom robotic gantry--the vision science equivalent of a turducken (i.e. turkey stuffed with chicken all stuffed with duck). We used the robotic gantry to capture stereo-image-scans of the scene from 6.5cm apart, a typical distance between the human eyes. We also used the gantry to align the nodal points of the camera and range scanner for each eye's view. This technique prevents half occlusions, regions of the scene that are imaged by the camera but not the scanner and vice versa. The result is a database made up of low-noise (200 ISO), high-resolution (1920x1080; 91 pix/deg), color-calibrated images with accurately co-registered range data at each pixel (error = +/- one pixel). We hope the database will serve as a useful resource for the research community.


Task-specific statistical methods for dimensionality reduction
In real estate, consider the task of determining whether a particular house is likely to increase in price. The likelihood that a house will increase in price may depend on its location, its size, its design, its materials, its condition, etc. But exactly how future price depends on the attributes listed above is not known. Some factors may be very predictive and some may have no predictive value. Furthermore, particular combinations of several factors may have more predictive power than any one individual factor. How does one determine the most useful feature combinations for estimating future house prices?
A similar issue exists in vision. Different stimulus features are useful for different sensory-perceptual tasks. For example, the relative activation of different color channels is useful for estimating hue and saturation, but is unlikely to be useful for estimating the speed of image motion. In the past, researchers chose stimulus features to study in the context of specific tasks because of intuition and historical precedent. We are developing and improving statistical methods for finding optimal stimulus features automatically. This is an exciting, blossoming, and foundational topic that has the potential to open up the rigorous study of natural and naturalistic stimuli in research on sensation and perception

Natural scene statistics & depth perception
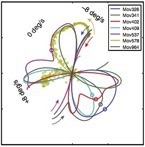
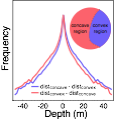
The human visual system has internalized a counter-intuitive statistical relationship between the shapes of object silhouettes and depth magnitude. In natural scenes, large depth discontinuities are more likely across edges bounding objects with convex than concave silhouettes (e.g. dinner plate vs crescent moon). In controlled experiments, we presented depth steps defined by disparity that were identical in every respect except the shape of the bounding edge. Human judgments of depth magnitude were biased in a manner predicted by the natural scene statistics.





We are also preparing a manuscript on slant perception that follows similar logic. First, we measured the distribution of slants in natural scenes. Next, we collected human psychophysical data on a custom psychophysical rig. Then we compared the pattern of biases in human slant perception to the pattern predicted by an ideal observer that had internalized the natural scene statistics. We found that humans behave as if they have internalized a close approximation to the naturally occurring distribution of slants.
Visuo-motor adaptation & recalibration
Rapid reaching to a target is generally accurate but also contains random and systematic error. Random errors result from noise in visual measurement, motor planning, and reach execution. Systematic errors result from systematic changes in the mapping between the visual estimate of target location and the motor command necessary to reach the target. These systematic changes may be due to muscular fatigue, or a new pair of spectacles. Humans maintain accurate reaching by recalibrating the visuomotor system, but no widely accepted computational model of the process exists. Given certain boundary conditions, the statistically optimal solution is a Kalman filter. We compared human to Kalman filter behavior. Their behaviors were similar: more variation in systematic error increased recalibration rate; more measurement uncertainty decreased recalibration rate; spatially asymmetric measurement uncertainty even caused different recalibration rates in different directions. We conclude that the relative reliability between the statistical variability of signals, and the relative uncertainty of error signals predicts the rate at which human observers recalibrate their visuo-motor system.


Visuo-haptic calibration
When visual and haptic cues are miscalibrated (signals disagree on average), the perceptual system re-calibrates so that the two signals more closely agree. We ran a carefully controlled study that measured the reliability (i.e. inverse variance) of visual and touch cues to slant. Then, under the condition in which the cue reliability was matched, we placed the cues in constant conflict (e.g. touch always indicated +5º than vision). After extensive adaptation, the calibration of the cues was remeasured. We found that the visuo-haptic system adapted so that the internal estimates of visual and haptic frontoparallel more closely matched under the conflicting conditions.
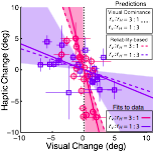
Visual adaptation
The influence of a visual cue on depth percepts can change after extensive tactile training in an unnatural environment. In natural scenes, the convex side of an edge is more likely to be the near side. Similarly, the concave side of an edge is more likely to be farther away. These facts are true because most objects are bounded and closed (i.e. objects are on average convex). The visual system has internalized this statistical regularity and uses it to estimate depth. For example, for identical disparity-defined depth step, more depth in perceived if the near surface has a convex silhouette than if it is concave. However, after extensive training in a virtual environment (~60 minutes) in which concave surfaces are always nearer, the affect of convexity on depth percepts is nearly reversed.

Monovision and the misperception of depth
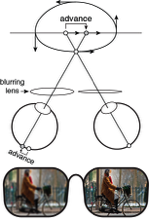

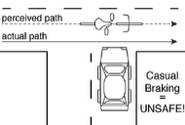
Monovision corrections are a common treatment for presbyopia. Presbyopia is the loss of focusing ability that affects all people over the age of fifty and is the reason that people wear reading glasses, bifocals, or progressive lenses. With monovision, each eye is fit with a lens that sharply focuses light from a different distance, causing the image in one eye to be blurrier than the other. Millions of people in the United States and Europe have monovision corrections, but little is known about how differential blur affects motion perception. We investigated by measuring the classic Pulfrich effect, a stereo-motion phenomenon first reported nearly 100 years ago. When a moving target is viewed with unequal retinal illuminance or contrast in the two eyes, the target appears to be closer or further in depth than it actually is, depending on its horizontal movement. The effect occurs because the image with lower illuminance or contrast is processed more slowly. The mismatch in processing speed causes a neural disparity, which results in the illusory motion in depth. What happens with differential blur? Remarkably, differential blur causes a reverse Pulfrich effect, an apparent paradox. Blur reduces contrast and should therefore cause processing delays, but the reverse Pulfrich effect implies that the blurry image is processed more quickly. The paradox is resolved because: i) blur reduces the contrast of high-frequency image components more than low-frequency image components, and ii) high spatial frequencies are processed more slowly than low spatial frequencies, all else equal. Thus, this new illusion—the reverse Pulfrich effect—can be explained by known properties of the early visual system.
In our first paper, we showed that the reverse Pulfrich effect can be induced by trial lenses (laboratory versions of spectacles). But monovision corrections are rarely delivered with spectacles. They are much more often prescribed with contact lenses or surgically implanted via intraocular lenses. A subseqeunt paper induced blur with contact lenses and showed that identically-sized reverse Pulfrich effects are caused by equivalent amounts of blur. One can safely conclude that intraocular lenses, a widespread and permanent adjustment to your visual system, can cause the same depth and motion misperceptions.
Quantitative analyses show that the misperceptions can be severe enough to have consequences for public safety. When driving, for example, the distance of moving objects may be misperceived by the width of a narrow lane of traffic. Fortunately, we have developed a non-invasive technique for eliminating the illusion in ecologically relevant situations. See the Patents page for more information.
We are currently investigating how the sizes of the classic and reverse Pulfrich effects are modulated are modulated by overall light-level, and why anomalous versions of the Pulfrich effects occur, in which the illusory motion trajectories that appear misaligned with the true direction of motion.
The motion illusion, and the paradigm we use to measure it, should prove useful for understanding how optical and image properties impact temporal processing, a fundamentally important but understudied issue in vision and visual neuroscience.
Classic Pulfrich
Reverse Pulfrich
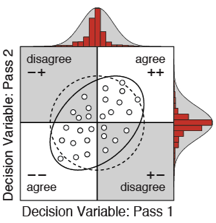
A recent paper shows that humans fall short almost exclusively because of internal noise; suboptimal computations play a negligble role. In a double pass experiment, in which each unique trial is presented twice, the ideal observer human decision variable correlation and response repeatability without additional free parameters. The result implies that the deterministic components of human speed processing are essentially optimal with natural stimuli. Furthermore, the results show that stimulus variability and internal noise equally limit performance. Stimulus variability thus misses half the story. These results motivate a renewed focus on characterizing performance-limiting factors external to the organism, and highlight the importance of image-computable ideal observers for the study of vision with natural signals.
Defocus estimation in individual natural images

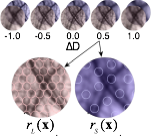
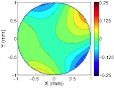
Vision begins with a lens system that focuses light near the retinal photoreceptors. A lens can focus light perfectly only from one distance. Natural scenes have objects at many distances, so regions of nearly all images will be at least a little bit out of focus; that is, defocus blur is present in almost every natural images. Defocus is used for many biological tasks: guiding predatory behavior, estimating depth and scale, controlling accommodation (biological auto-focusing), and regulating eye growth. However, before defocus can be used to perform these tasks, defocus itself must first be estimated.
Surprisingly little is known about how biological vision systems estimate defocus. The computations that make optimal use of available defocus information are not well-understood, little is known about the psychophysics of human defocus estimation, and almost nothing is known about its neurophysiological basis. Very little existing work has examined defocus estimation with natural stimuli. Given that defocus may be the most widely available depth cue on the planet, we decided to dig into the problem.
We have developed a model of optimal defocus estimation that integrates the statistical structure of natural scenes with the properties of the vision system. We make empirical measurements of natural scenes, account for the optics, sensors, and noise of the vision system, and use Bayesian statistical analyses to obtain estimates of how far out of focus the lens is. From a small blurry patch of an individual image we can tell how out-of-focus that patch of image is. Our results have implications for vision science, neuroscience, comparative psychology, computer science, and machine vision.
We are currently investigating human defocus discrimination in natural images using psychophysical methods and a custom built three-monitor rig. We are also developing improved algorithms for auto-focusing digital cameras and other digital imaging systems, without need for specialized hardware or trial-and-error search.
Also see the Patents page for more information.


Model
Human
Continuous target-tracking psychophysics
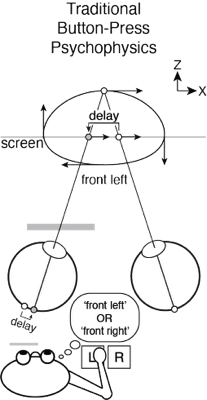


Traditional button-press psychophysical method is the current gold standard for measuring sensory-perceptual processing. Typically, a stimulus is presented, the subject observes the stimulus, and reports an aspect of the percept with a binary response, often via a button press. This method is exquisitely sensitive, but it generally requires many trials of each observer, because the information associated with each trial is quantized (i.e. button 1 vs. button 2) and the pace of data collection is slow (e.g. thirty data points per minute). As a result, data collection is often laborious for the subject. Furthermore, traditional psychophysics generally requires that observers follow moderately sophisticated verbal instructions (e.g. press the left button if the target appears to be moving left when it is in front of the screen and right otherwise), a requirement that rules out infants, young children, and animals (unless extensive non-verbal training is provided).
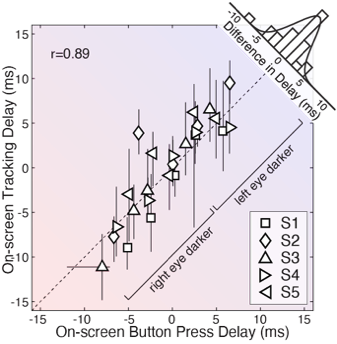
Continuous target tracking psychophysics provides an alernative that rapidly addresses these issues and, at the same time, reveals the time course of visual processing. We have applied target tracking to the specific problems of estimating visual sensitivity for position changes and estimating millisecond-scale differences in visual processing between the eyes. The latter task is relevant to measuring and characterizing the classic and reverse Pulfrich effects, which may applications in clinical ophthalmology. In both tasks, we have shown that traditional and target tracking psychophysics yield equivalent estimates of the task relevant quantities, but that estimates from target tracking can be obtained much more quickly.
The level of agreement between the estimates derived from the two methods is striking, especially given the enormous differences between them. One method—traditional button-press psychophysics—presented a target stimulus following a stereotyped motion trajectory (i.e. a near-elliptical path through a 3D volume of space) and obtained a binary response. This binary response reflected an aspect of the observer's percept, and the response is essentially independent of the temporal properties of the motor system. The other method—target-tracking psychophysics—presented a target stimulus following an unpredictable motion trajectory (i.e. a random walk in the 2D plane of the display monitor) and obtained the continuous motor response of the observer. This continuous response is fundamentally constrained to reflect the temporal properties of both the visual and motor systems. And yet, the estimates of interocular delay from the two methods agree with one another on average to within a fraction of a millisecond, and in each individual condition to within a few milliseconds. The fact that substantially different stimuli and substantially different experimental paradigms yield near-identical estimates of interocular delay strongly suggests that both paradigms are measuring the same underlying quantity.